Concepts
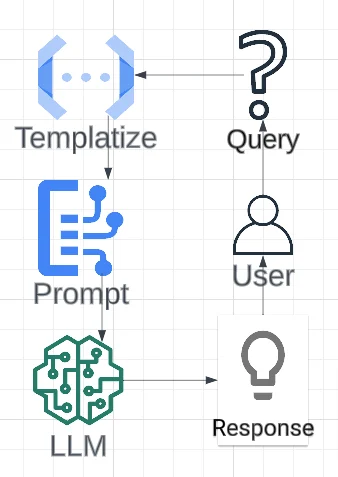
The LLM Workflow with Featureform
Large Language Models (LLMs) are pre-trained models that take a text prompt as input and generate a response based on the prompt.
All LLM workflow revolved around the following operation: