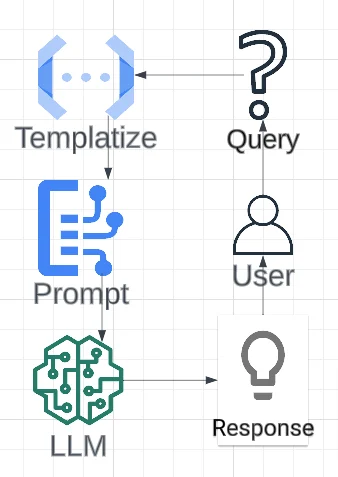
Large Language Models (LLMs) are pre-trained models that take a text prompt as input and generate a response based on the prompt.All LLM workflow revolved around the following operation:To achieve our desired output, we can do one of two things: Improve the prompt, especially by adding additional context (Retrieval Augmented Generation) Fine-tune the LLMThough, there are prompt construction tricks that achieve better results in practice; the most reliable and most impactful way to improve a prompt is to add more context when it’s available. Fine-tuning is essentially providing this same context through a different API than the prompt.So, in short, the best way to improve your LLM’s systems performance is to feed in data as context! Even with this new ML paradigm, it all comes down to data.
When to use Retrieval-Augmented Generation and when to use Fine-Tuning
There are two ways to make your LLM system better using your private data: Retrieval Augmented Generation and Fine-Tuning. There are a few things to take into consideration, when deciding:
Fine-tuning does not easily “memorize” new information in practice. It often ends up mimicking the style of the content it’s being fine-tuned on. On the other hand, the typical use case of RAG is to use relevant information to help the LLM formulate a better response.
Similar to the reason above, if you’re using contextual information to try to eliminate hallucination, RAG is likely to work better since the information in the query will be heavily weighted. With fine-tuning, unless you’ve used a massive dataset, it’s likely to not memorize information and to still hallucinate.
Fine-tuning requires much more data to achieve desired results. RAG can work with sparse data or small data sets since it only pulls relevant data at inference time.
Depending on the nature of your data, you may be very sensitive to revealing your training data. With fine-tuning, all the data you used has potential to be revealed given the right prompt. On the other hand, with RAG, only the data that you feed into that specific query may be revealed. If you’re using a user’s own data as context, this might not be a problem. RAG dramatically drops the scope of data that may be revealed to simply what’s in the prompt.
We typically see far better results when using RAG. It’s much cleaner and controllable. The only exception is when you are trying to match a writing style. In that case fine-tuning often works much better. For example, if you want to use an LLM to respond to questions on slack, you can fine-tune it on all the answers you’ve given in the past to have it sound like you.So in short: Fine-tuning to match a writing style RAG to inject context/information