Retrieval Augmented Generation (RAG) Workflow for Chatbots with Featureform
The retrieval augmented generation workflow pulls information that’s relevant to the user’s query and feeds it into the LLM via the prompt. That information might be similar documents pulled from a vector database, or features looked up from an inference store.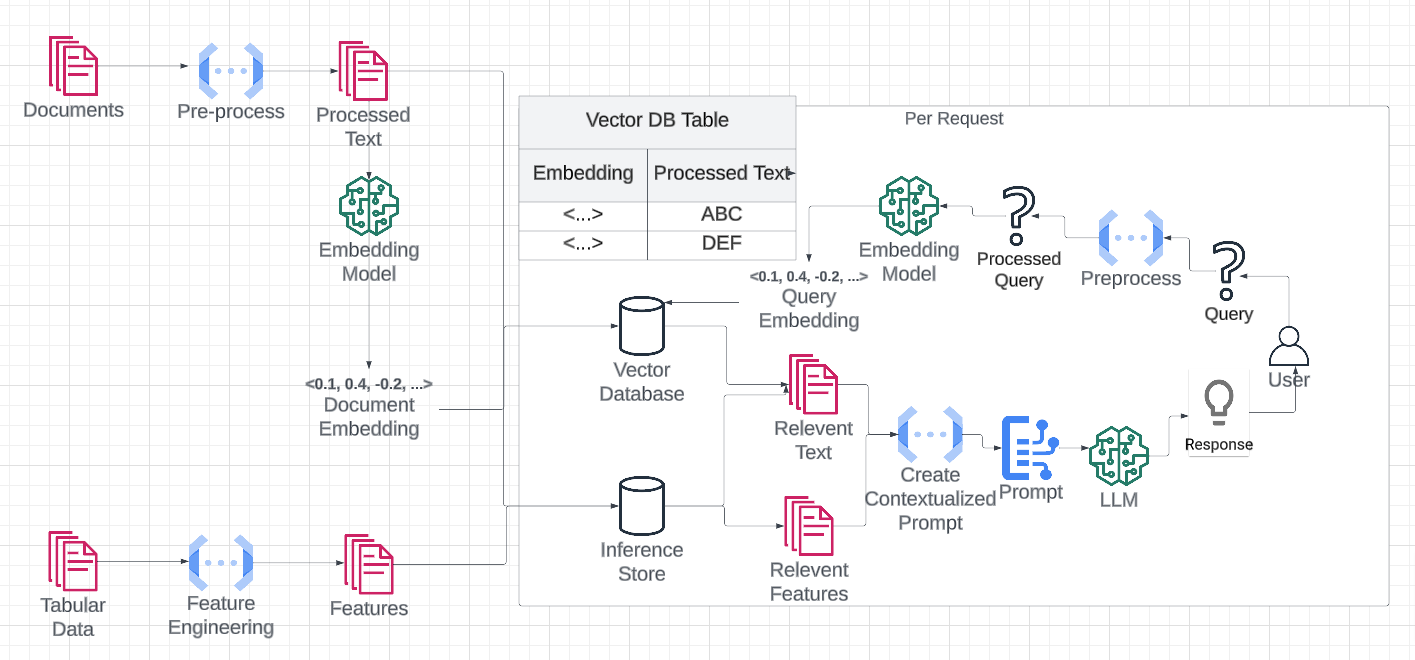
RAG workflow explained
Indexing Documents for Similarity Search
It’s common to retrieve text that’s relevant to a user’s query.Registering your Documents
To start using Featureform for RAG, we should register the documents that we plan to use as context. CSV File For a CSV file on our local system, we can do the following:Pre-Processing
Our text files may be imperfect to use as context. We need to choose the right size and density of data to maximize the information we provide to our final prompt. If our text is too long, we may choose to chunk it. If it’s too short, we may choose to concatenate multiple into one. In almost every situation, there’s other sorts of cleaning of data that may have to be done. Chunking We can chunk by doing things like splitting on periods to create sentences or new lines for paragraphs. Langchain also has a set of text chunkers that can be used as well. Concatenation To concatenate, we can add together text that are relevant to each other. For example, we can choose to append all of the messages in a slack thread as one document. Cleaning Data is never clean. We may want to remove formatting and other imperfections using transformations.Indexing / Embedding Data
Now that we have our text cleaned up, we need to index it for retrieval. To do so, we’ll create an embedding of the text. We’ve written a long form article on embeddings. However, for this situation, you can simply think of them as a specialized index for similarity search. Text that’s similar according to the embedding model, will be near each other in N-Dimensional space. We’ll use a vector database for retrieval.OpenAI’s ADA
We can use the ADA model from OpenAI to embed our documents. Note that this is a different model than GPT. It’s purpose it to convert text into embeddings for nearest neighbor lookup.HuggingFace sentence_transformers
sentence_transformers with HuggingFace is our recommended way of embedding models. It’s fast and free! The quality of embeddings will likely be slightly worse than ADAs though.Define and Manage Features and Embeddings
Now that we have built our datasets, we can start to mark columns as our features and embeddings and place them in our vector database.Defining infrastructure providers like vector databases
In localmode, we’ll often want to use an external vector database to index and retrieve our vectors. Even though our embeddings will be computed locally (or via API if using ADA), the final embeddings will be written to a vector database. PineconeDefining Feature and Embedding Columns
Now that we have our vector databases registered, we can specify the columns that make up our embeddings and our features. Note that embeddings are used to retrieve entity IDs, and that the actual text should be registered as a separate entity.Using the Featureform Client and Dashboard
We can runfeatureform dash to run and visualize our resources. We can go to http://localhost:3000 to look through it.