Introduction
Featureform allows data scientists to define their model’s features, labels, and training sets in their logical representations. In reality, the logical definitions are split across different real components: the data source, the transformations, the inference store, the training store, and all their underlying data infrastructure. Featureform then coordinates a set of infrastructure providers to make the real components match each resource’s logical representation. Those real components can then be served for training and inference, and the logical resources can be explored via the feature registry. Our enterprise edition also provides support for access control, audit logs, and other governance capabilities.Using Featureform
Configure Infrastructure Providers
Featureform coordinates a set of infrastructure providers to act together as a feature store. Before transformations, features, and other resources can be defined, an initial set of providers must be configured. This is done via a Python API and applied via the Featureform CLI. Registering Infrastructure ProvidersDefine Features, Labels, and Training Sets
Once the infrastructure is configured, features and training sets can be created. This begins by registering a set of primary data sources, often followed by defining a DAG of transformations. Once the transformed sources are created, features and training sets can be defined. Other metadata such as descriptions, variants, and names are also defined in this step. In the enterprise editions, governance rules that the organization created will be enforced here. All these steps are done via a Python API and applied via the Featureform CLI. Defining Features, Labels, and Training SetsServe for Inference and Training
Once the training sets and features have been created, they can be served. Featureform provides a Dataset API for training and an Inference API for feature serving. Serving for Inference and TrainingExplore the Feature Registry
Whether working alone locally or as part of a large enterprise organization, Featureform resources can be explored via the Feature registry. It provides data lineage, transformation logic, ownership, and more. A user can see which models are using which features, which features are stored on which providers, and other cross-sections of exploring the metadata. Exploring the Feature RegistryResource Types
To use Featureform, a user will define all of their resources declaratively in Python, and use the CLI to apply it. Featureform will then create all the required resources via the registered providers. It will schedule and run the required transformations to create the defined features and training sets.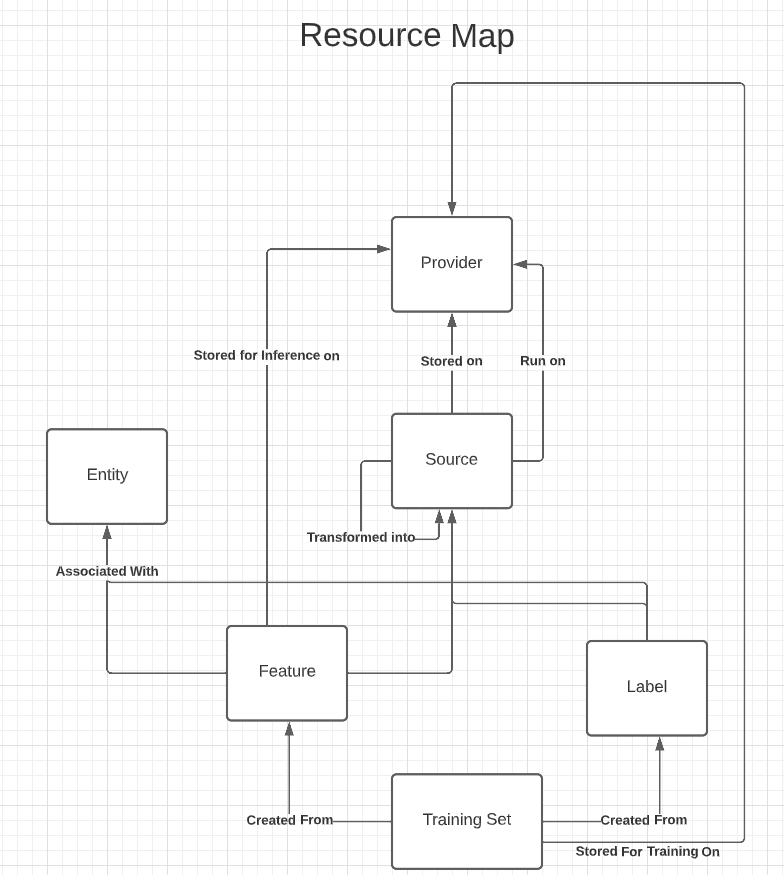
The Featureform Resource Map